- Topic1/3
23k Popularity
38k Popularity
3k Popularity
415 Popularity
690 Popularity
- Pin
- Hey fam—did you join yesterday’s [Show Your Alpha Points] event? Still not sure how to post your screenshot? No worries, here’s a super easy guide to help you win your share of the $200 mystery box prize!
📸 posting guide:
1️⃣ Open app and tap your [Avatar] on the homepage
2️⃣ Go to [Alpha Points] in the sidebar
3️⃣ You’ll see your latest points and airdrop status on this page!
👇 Step-by-step images attached—save it for later so you can post anytime!
🎁 Post your screenshot now with #ShowMyAlphaPoints# for a chance to win a share of $200 in prizes!
⚡ Airdrop reminder: Gate Alpha ES airdrop is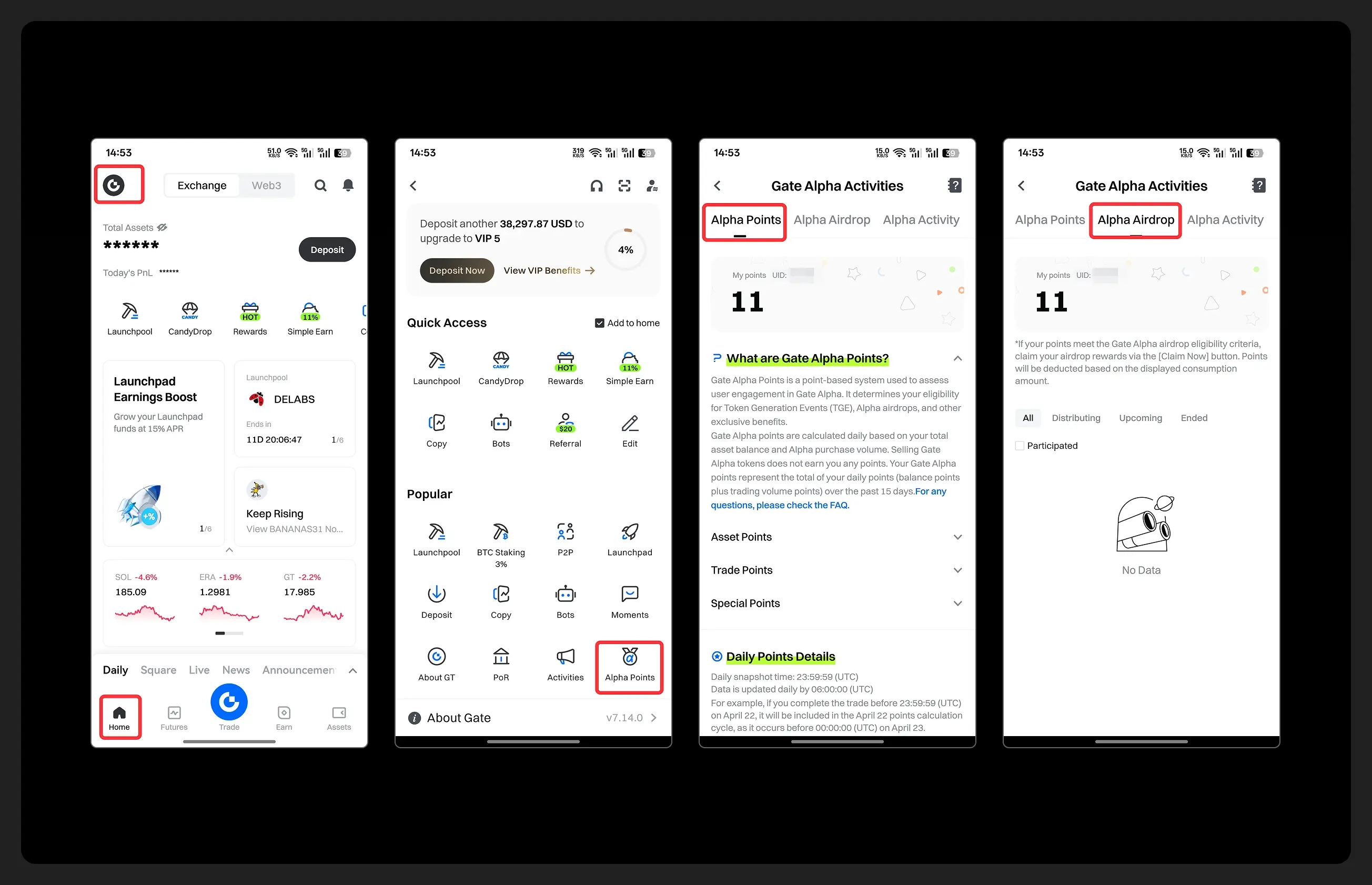
- Gate Futures Trading Incentive Program is Live! Zero Barries to Share 50,000 ERA
Start trading and earn rewards — the more you trade, the more you earn!
New users enjoy a 20% bonus!
Join now:https://www.gate.com/campaigns/1692?pid=X&ch=NGhnNGTf
Event details: https://www.gate.com/announcements/article/46429
- Hey Square fam! How many Alpha points have you racked up lately?
Did you get your airdrop? We’ve also got extra perks for you on Gate Square!
🎁 Show off your Alpha points gains, and you’ll get a shot at a $200U Mystery Box reward!
🥇 1 user with the highest points screenshot → $100U Mystery Box
✨ Top 5 sharers with quality posts → $20U Mystery Box each
📍【How to Join】
1️⃣ Make a post with the hashtag #ShowMyAlphaPoints#
2️⃣ Share a screenshot of your Alpha points, plus a one-liner: “I earned ____ with Gate Alpha. So worth it!”
👉 Bonus: Share your tips for earning points, redemption experienc
- 🎉 The #CandyDrop Futures Challenge is live — join now to share a 6 BTC prize pool!
📢 Post your futures trading experience on Gate Square with the event hashtag — $25 × 20 rewards are waiting!
🎁 $500 in futures trial vouchers up for grabs — 20 standout posts will win!
📅 Event Period: August 1, 2025, 15:00 – August 15, 2025, 19:00 (UTC+8)
👉 Event Link: https://www.gate.com/candy-drop/detail/BTC-98
Dare to trade. Dare to win.
Data Asset Chain: A New Infrastructure of Web3 that Unlocks the Trillion-Level Storage Market Potential
Data Assetization: Unlocking New Approaches to the Trillion-Level Storage Market
In today's digital age, the phrase "data is the new oil" has become a common consensus among people. However, in reality, most people can only act as bystanders, unable to truly own and utilize these data resources. We create content online every day, provide behavioral data, and even supply training materials for AI, but very few can actually reap the rewards from it.
Currently, 95% of the world's AI training data is controlled by a handful of tech giants, which are defining the way the world operates with their complete "data asset pools." Meanwhile, the data infrastructure construction in the Web3 world is far from mature. The storage costs of Ethereum are exorbitant, and some scalability projects also require massive amounts of funds for temporary off-chain data storage. At the same time, many AI companies are still relying on web crawlers to collect low-quality data from public web pages, while areas such as data authorization, copyright management, and content incentives are almost completely blank.
This is an economy with an annual output value of 3 trillion dollars, yet it lacks its own "operating system".
A more fundamental question is being re-examined: what kind of data is truly valuable? Is it the static accumulation of files, or is it the data assets that can be read, authorized, invoked, and traded? The answer is gradually becoming clearer. Future competition will no longer be limited to the amount of data stored, but rather how to use data and unlock its value.
The Undervalued Trillion-Dollar Market: Data Usage Rights and Monetization Issues
In this highly digitalized era, everyone generates a large amount of data every day: comments on social platforms, created content, behavioral traces of product usage, uploaded images and videos, and even the vast amounts of public material inadvertently provided to AI models.
It is worth pondering that even though Web3 advocates "user ownership" and "decentralization," there is almost a blank slate when it comes to truly usable, controllable, and monetizable data infrastructure. In other words, on-chain assets can be traded, combined, and incentivized, but data remains in a "silo" state, unable to flow effectively or generate revenue.
Several typical problems have always existed:
Developers are unable to put data on the chain at a reasonable cost, especially for large volumes of data, which is extremely expensive under the current infrastructure, making it unsustainable for daily use or commercial implementation.
Even if the data is successfully on the chain, it is still difficult to efficiently call and combine it, with high latency and weak interfaces, resulting in the cost of "data usage" remaining relatively high.
The lack of standardized data authorization and charging mechanisms prevents content creators or platform providers from establishing a trustworthy "data commodity" trading model, making it impossible to truly "sell" a piece of data.
Separation of storage and computation means that using data still relies on centralized tools or off-chain logic, making the Web3 data experience incomplete.
These structural issues directly lead to the difficulty in implementing the concept of "data as an asset." We often say "empower data," but once it involves specific actions such as authorization, invocation, and transactions, we find that there is no real on-chain platform that can support these needs.
The emergence of new data infrastructure projects aims to address these core contradictions. They do not simply provide "cheaper storage"; instead, they seek to redefine the role of data on the chain from the perspective of programmability, executability, and incentivization. Data is transformed from a passive storage file into a "native on-chain asset" that possesses rules, value, and behavioral capabilities.
Core Logic: It's not about storing data, but about unlocking the value of data.
In the traditional blockchain context, when talking about "data", people first think of "storage"—writing data into the blockchain or off-chain solutions to ensure its availability and immutability. This is precisely the main focus of some storage protocols: emphasizing that data is stored for a long time, stored securely, and stored cheaply.
But the perspective of the new generation of data infrastructure is completely different. From the moment they were born, they were not designed to be a "cheaper hard drive", but rather centered around a core question: how to make data truly a "capable" on-chain asset that can participate in circulation, be used, and create value.
This is also the fundamental distinction between the new generation of data infrastructure and traditional storage protocols – it is not about storing data, but about unlocking the value of data.
In the Web3 world, "storage" has always been a costly operation. For example, the on-chain storage costs of Ethereum can reach hundreds of thousands or even millions of dollars per GB, greatly limiting the development of data-related applications.
The new generation of data infrastructure significantly reduces storage costs through underlying architecture optimization and resource scheduling mechanisms while ensuring data security and availability. This is highly appealing for scenarios such as AI model training, content platforms, and social protocols that require processing massive amounts of data.
Traditional storage protocols often emphasize that "data cannot be lost after being put on the chain". However, when it comes to reading this data, there are often issues such as complex calls, high latency, and non-standard interfaces.
The design concept of the new generation of data infrastructure is more akin to a database: data is not "archived" but "available." Developers can read and process on-chain data in a familiar way with low latency and high efficiency, which is crucial for applications that require real-time interaction or high-frequency calls.
Some emerging projects are fully compatible with EVM, allowing developers to use Ethereum ecosystem tools such as Solidity, Hardhat, and Foundry to directly build data-related contract logic.
This not only lowers the threshold for the migration from Web2 to Web3, but also allows existing Ethereum developers to seamlessly build DApps around "data assets," expanding new application scenarios such as authorized data markets, on-chain AI processing platforms, and content royalty management systems.
Unlike a single chain structure, some emerging projects adopt a multi-ledger architecture, allowing different types of data to set different storage cycles and access permissions. For example, certain temporary data can have an automatic destruction time set, sensitive data can be configured with access verification logic, and public data can have open query permissions.
This flexible "data lifecycle management capability" allows the new generation of data infrastructure to meet the complex needs of various fields such as AI, content, social, and finance.
This is the most differentiated aspect of the new generation of data infrastructure. On these platforms, data is not merely an "inactive storage" block of information; it can embed rules such as pricing, authorization, and usage, and be automatically executed through smart contracts.
In other words, each piece of data carries a "contract awareness" that can:
This form of "programmable data assets" makes data no longer static content, but rather a new type of on-chain asset category that is truly tradable, incentivizable, and combinable. The positioning of the new generation of data infrastructure is no longer a traditional "decentralized storage protocol," but rather an infrastructure platform aimed at the future data economy. It integrates storage, usage, trading, and execution, creating a complete closed loop for data from generation to circulation to monetization.
For developers, it is a low-threshold, high-efficiency tool platform; for creators, it is a trustworthy and controllable value release channel; and for the entire Web3 ecosystem, it may be the key to unlocking a new paradigm of "data as an asset."
Data infrastructure is becoming the new core battlefield.
In recent years, the attention in the cryptocurrency industry has mostly focused on public chain performance, DeFi innovations, and NFT applications. However, with the rapid development of AI, large models, and content creation, "data," the most fundamental yet strategically valuable resource, is once again becoming the "hard currency" in the consensus of the industry.
Especially in the context of Web3, the role of data is not just information recording, but also serves as the raw material for a series of core mechanisms such as smart contract execution, AI model training, identity mapping, and content rights confirmation. Data infrastructure is no longer a marginal role but is moving towards the core of the industry.
We can clearly see this trend from a series of recent events:
These seemingly independent events actually point to the same reality: Web3 is entering a new stage of "data as a core asset," with an exponential increase in the demand for on-chain data that is "usable, controllable, and monetizable."
However, we still lack a universal, stable data infrastructure that supports large-scale calls.
Current solutions either focus on storage but cannot be invoked (such as certain storage protocols), or only address specific vertical issues (such as projects targeting IP licensing). There has yet to be a fully functional underlying chain designed for "general data assets."
This is why the entry point of the new generation of data infrastructure is so critical. They not only fill the gap of "data storage + invocation + transaction," but also provide a combinable, scalable, and extensible solution path for the entire ecosystem through programmable data and smart contract execution mechanisms.
In other words, this is the "data main chain" that the market has been waiting for.
Data is not just a "resource", but should be an "asset".
Storage is the starting point, but not the end point. To truly unlock the value of data, a complete set of technologies and architectures around "usage rights, incentive mechanisms, and contract control" is needed.
The new generation of data infrastructure being built is a blockchain underlying that truly transforms "data" into "assets."
From content creators to AI model trainers, from decentralized social media to on-chain computing platforms, as long as you are building a data-dependent Web3 product, these emerging data infrastructures may become options you need to consider.
The future of data is not just about "putting it in," but rather "how to create value and then output it." This process requires a chain specifically designed for this purpose.