Datenverfügbarkeit und das Datenschutzproblem
In diesem Modul wird das Konzept der Datenverfügbarkeit in modularen Blockchains vorgestellt und erklärt, warum diese für Rollups unverzichtbar ist. Es werden die Einschränkungen aktueller öffentlicher Datenverfügbarkeits-Layer dargestellt. Dabei sind Transaktionsdaten für jedermann einsehbar, was für Unternehmen und regulierte Branchen erhebliche Datenschutzrisiken birgt. Darüber hinaus wird die Entwicklung privater Rollups erläutert und dargelegt, weshalb der Bedarf an verschlüsselter Datenverfügbarkeit jetzt besonders dringlich ist.
Datenverfügbarkeit verstehen
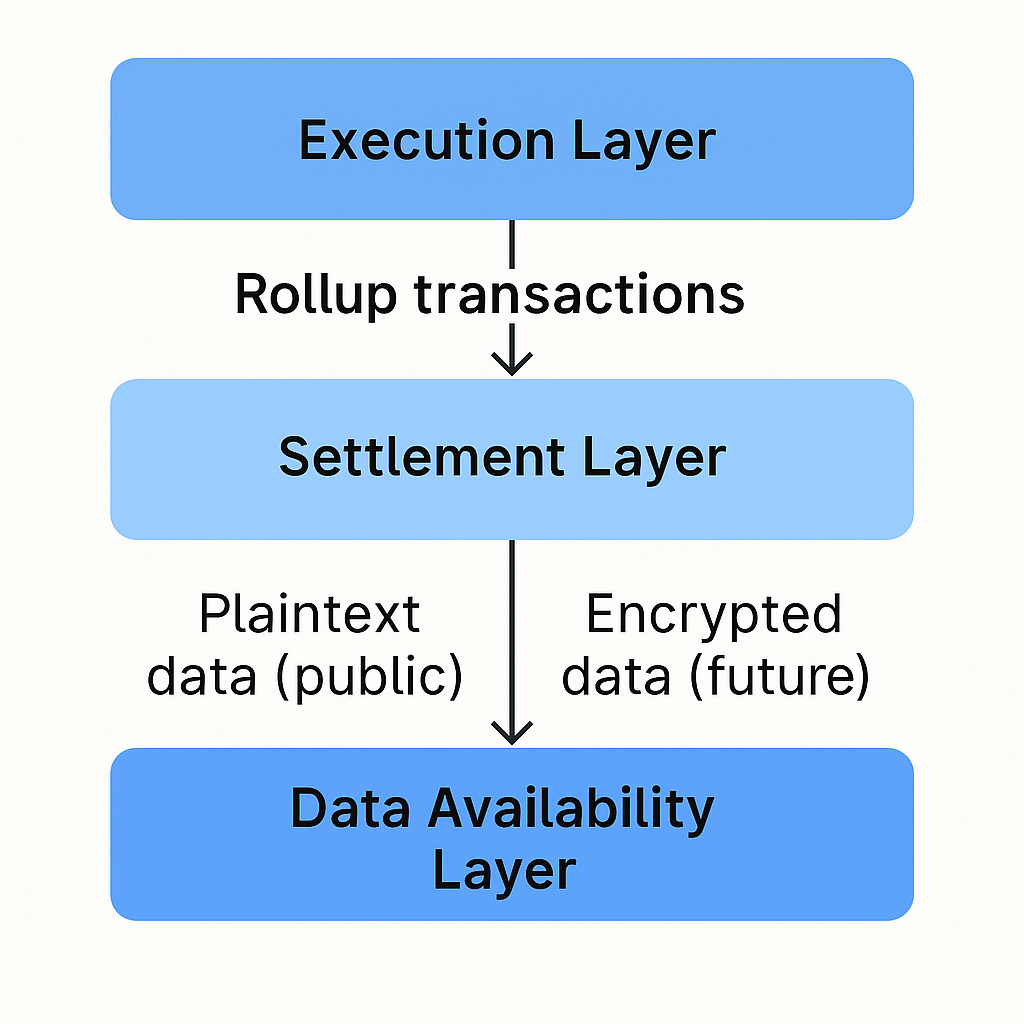
Datenverfügbarkeit bildet ein zentrales Grundprinzip moderner modularer Blockchains und Rollup-Architekturen. Sie beschreibt die verlässliche Zusicherung, dass sämtliche zur Überprüfung von Zustandsübergängen einer Blockchain erforderlichen Daten öffentlich und für jeden zugänglich sind, der das Netzwerk validieren möchte. Fehlt diese Verfügbarkeit, können Nutzer und Validatoren den Zustand der Kette nicht rekonstruieren, keine betrügerischen Handlungen aufdecken und Sequencer nicht auf korrektes Verhalten prüfen. Besonders bei Rollups, die die Ausführung auf eine eigene Schicht auslagern und dabei auf eine Basisschicht für Sicherheit setzen, ist Datenverfügbarkeit entscheidend: Sollte die Transaktionsdatenübermittlung an die Basisschicht verhindert werden, können Nutzer weder Vermögenswerte abheben noch ihre Besitzrechte belegen – das Vertrauensmodell des Rollups wäre damit grundlegend gestört.
Traditionelle monolithische Blockchains wie Bitcoin oder Ethereum verankern die Datenverfügbarkeit direkt im Konsensverfahren: Jede Node speichert und verteilt sämtliche Transaktionen. Modulare Architekturen trennen diese Funktion und führen spezialisierte Datenverfügbarkeitsschichten wie Celestia, Avail und EigenDA ein. Diese Schichten bieten bandbreitenoptimierte Ansätze für die Veröffentlichung großer Transaktionsdaten, häufig unter Einsatz kryptografischer Verfahren wie Erasure Coding und Data Availability Sampling. So können auch Light Clients überprüfen, ob Daten tatsächlich bereitgestellt wurden, ohne sie vollständig herunterladen zu müssen. Diese Entwicklung hat das Wachstum von Rollup-Ökosystemen deutlich beschleunigt, denn sie reduziert die Kosten erheblich und verbessert die Skalierbarkeit gegenüber der Speicherung auf der Ethereum-Basisschicht.
Gleichzeitig bringt die öffentliche Ausgestaltung bestehender Lösungen für Datenverfügbarkeit eine entscheidende Einschränkung mit sich: Sämtliche veröffentlichten Daten sind für alle vollständig sichtbar. Während dieses Prinzip für öffentliche Rollups und Endnutzeranwendungen geeignet ist, stellt es für Unternehmen, regulierte Institutionen und datenschutzsensible Anwendungsbereiche eine gravierende Hürde dar. Wichtige Informationen, unternehmenseigene Geschäftslogik oder persönliche Nutzerdaten dürfen nicht offen auf einer öffentlichen Blockchain erscheinen – andernfalls drohen Verletzungen von Geheimhaltungspflichten oder regulatorischen Anforderungen. Der daraus resultierende Zielkonflikt zwischen Nachprüfbarkeit und Diskretion bildet den Antrieb für die Entwicklung verschlüsselter Lösungen für Datenverfügbarkeit.
Die Datenschutzlücke in bestehenden Schichten für Datenverfügbarkeit
Viele Schichten für Datenverfügbarkeit gehen davon aus, dass Transparenz notwendig und wünschenswert sei. Der Gedanke unterstützt zwar Dezentralisierung und Nachvollziehbarkeit, führt jedoch dazu, dass Rohtransaktionsdaten jedem offenliegen, der die Blockchain beobachtet. Selbst wenn Anwendungen auf Anwendungsebene bestimmte Datenteile verschlüsseln, bleiben Metadaten wie Reihenfolge, Häufigkeit und Umfang der Transaktionen öffentlich – daraus lassen sich oft Rückschlüsse auf Nutzerverhalten oder institutionelle Abläufe ziehen. So könnte etwa eine Bank, die ein Rollup für interne Abwicklungen nutzt, durch die Analyse eingereichter Datenblöcke ungewollt Handelszeiten oder Volumenmuster offenbaren.
Gerade in Branchen mit strengen Vorgaben ist diese Datenschutzlücke kritisch. Anwendungen im Gesundheitsbereich, die Patientendaten verwalten, Identitätslösungen mit personenbezogenen Daten oder ERP-Systeme, die unternehmensspezifische Lieferketten übernehmen, können sich keine Informationslecks erlauben. Eine Offenlegung dieser Daten im Klartext – selbst bei Pseudonymisierung – widerspricht Regularien wie HIPAA, DSGVO oder anderen länderspezifischen Datenschutzregeln. Deshalb schrecken viele Branchen trotz der Skalierungsvorteile von Rollups und modularen DA-Schichten vor deren Einsatz zurück, solange strukturierter Datenschutz auf Ebene der Datenverfügbarkeit fehlt.
Modulare Blockchains und der Aufstieg privater Rollups
Die Einführung modularer Blockchain-Architekturen hat grundlegende Veränderungen bei Skalierbarkeit und Funktionalität herbeigeführt. In diesem Modell werden die drei zentralen Aufgaben – Ausführung, Abwicklung und Datenverfügbarkeit – voneinander getrennt und durch unabhängige Schichten realisiert. Rollups dienen als Ausführungsumgebungen, die Transaktionen bündeln und komprimierte Nachweise an eine Abwicklungsschicht weiterleiten. Die DA-Schichten stellen wiederum sicher, dass die relevanten Transaktionsdaten zur Überprüfung bereitstehen. Diese klare Trennung erlaubt jeder Schicht, sich auf ihre Kernfunktionen zu spezialisieren – das erhöht den Durchsatz und senkt die Kosten im Vergleich zu monolithischen Systemen.
Im Zuge dieser Entwicklung haben sich neue Rollup-Frameworks etabliert, darunter der OP Stack von Optimism, Arbitrum Orbit, das Chain Development Kit von Polygon und der ZK Stack von zkSync. Sie bieten wiederverwendbare Bausteine, um maßgeschneiderte Rollups für spezifische Anwendungsfälle aufzusetzen – vom Gaming über Endkunden-Anwendungen bis hin zu institutionellen Finanzlösungen. Die meisten dieser Stacks setzen jedoch, standardmäßig, auf öffentliche Datenverfügbarkeit. So entsteht eine kritische Lücke für Projekte mit Anforderungen an Vertraulichkeit.
Aus dieser Notwendigkeit hat sich das Konzept privater Rollups entwickelt. Ein privates Rollup agiert ähnlich wie ein Standard-Rollup bezüglich Ausführung und Abwicklung, integriert aber Datenschutz auf mehreren Ebenen – bei Transaktionsdaten, Zustandsveröffentlichungen und insbesondere der Datenverfügbarkeitsschicht. Bei privaten Rollups werden die an die DA-Schicht übermittelten Daten verschlüsselt, sodass ausschließlich autorisierte Parteien die vollständige Transaktionshistorie entschlüsseln können. So lassen sich die Skalierbarkeit und Kombinierbarkeit öffentlicher Rollups nutzen, wobei die für Unternehmen essenzielle Vertraulichkeit gewahrt bleibt.
Warum Datenschutz bei Datenverfügbarkeit jetzt entscheidend ist
Der Fokus auf verschlüsselte Datenverfügbarkeit resultiert nicht aus einem theoretischen Forschungsinteresse, sondern ist eine direkte Antwort auf reale Hindernisse bei der flächendeckenden Einführung. In den letzten zwei Jahren haben führende Finanzinstitute, Gesundheitseinrichtungen und Behörden Blockchain-Pilotprojekte durchgeführt. Wenngleich sie die Vorteile programmierbarer, transparenter Infrastrukturen schätzen, stießen sie auf Compliance-Probleme, sobald sensible Informationen auf öffentlichen Ledgers sichtbar wurden. In zahlreichen Fällen wurden Pilotprojekte entweder auf Testsysteme beschränkt oder ganz eingestellt, weil interne Richtlinien zum Datenumgang nicht eingehalten werden konnten.
Parallel dazu entwickelt sich das Blockchain-Ökosystem in Richtung Modularität. Da sich Datenverfügbarkeit als eigene Schicht durchgesetzt hat, entsteht die Möglichkeit, Datenschutz direkt an dieser grundlegenden Stelle zu etablieren, anstatt sich lediglich auf Verschlüsselungsverfahren in späteren Schichten zu verlassen. Verschlüsselte Datenverfügbarkeit gewährleistet, dass die Sicherheits- und Betrugspräventionsmechanismen der Rollups erhalten bleiben, während sie gezielte Offenlegungen gegenüber Prüfern, Aufsichtsbehörden oder Partnern ermöglicht. Diese selektive Transparenz ist für hybride öffentliche-private Anwendungsfälle essentiell, bei denen einzelne Teilnehmer auf Transparenz, andere aber auf Vertraulichkeit angewiesen sind.
Auch der Zeitpunkt ist bedeutsam: Im Zuge anstehender Weiterentwicklungen führender DA-Lösungen, zum Beispiel dem Enigma-Upgrade von Avail, wird erstmals eine produktionsreife Implementierung für nativ verschlüsselte Datenblöcke mit überprüfbaren Verfügbarkeitsnachweisen bereitgestellt. EigenDA und Walacor prüfen vergleichbare Funktionen und schaffen so ein Wettbewerbsumfeld, in dem datenschutzfreundliche Datenverfügbarkeit rasch zum Standard werden könnte. Mit zunehmender Reife modularer Ökosysteme und wachsender Akzeptanz auch außerhalb der Krypto-Community dürfte verschlüsselte Datenverfügbarkeit zukünftig als Grundvoraussetzung für Rollup-Lösungen in Unternehmen und Verwaltung gelten.
Verwandte Kurse

DAO-Grundlagen
DAO-Grundlagen

Datenschutz und Krypto
Datenschutz und Krypto

Kryptosteuer
Kryptosteuer

Einführung in Masternode-Tokens
Einführung in Masternode-Tokens

Stablecoin-Grundlagen
Stablecoin-Grundlagen
